Predicting Movie Review Sentiment Using IMDB Web Data
It’s been an arduous, if not exciting last three weeks of bootcamp work. Between exercises, projects, networking and trying to absorb all of the material, the course has shaped up to be a real juggling act of effort and time management. While the entire experience has proved enlightening thus far, the whole reason for signing up for the bootcamp was to gain tangible, applicable skills in data science. I certainly haven’t been disappointed yet, and the fundamentals of data science that we’ve been learning were showcased first hand in our most recent assignment: Project Luther.
The goal of the project is fairly simple. Using online data from any number of film and cinema websites, we were asked to build a predictive model for a continuous target variable. The variable we chose was not important, so long as it’s numerical and (somewhat) continuous. I decided to predict movie review sentiment, or how the public feels about the quality of a certain film. As a proxy for review sentiment, I decided to use IMDB user score since most reviews are left by casual viewers instead of professional critics, giving a more representative view of public sentiment. One of the nice things about the IMDB website is that each movie page has a number of key features that could be used as regressors in my analysis. Namely, these include domestic total gross revenue, budget, primary and secondary genre, year of release, month of release, MPAA rating, runtime, number of IMDB reviews, number of Oscar wins, and Metacritic score.
The business case for the project was simple to come up with. A more positive public sentiment for a film leads to more tickets sold at the box office, more rentals and purchases of the film, the possibility of franchising and signing advertising deals, and also furthers the reputation of the actors and director of the film. The real challenge was making the model as accurate as possible, and doing so without overfitting. After scraping all of the relevant features from the IMDB website, I had data on 720 films to build my model and test which regressors are statistically significant. I started out by visualizing the data, and noticed a couple features seemed to have a logarithmic relationship with the target. Specifically, number of IMDB user reviews and domestic total gross revenue appear to have a nonlinear relationship with IMDB user score.
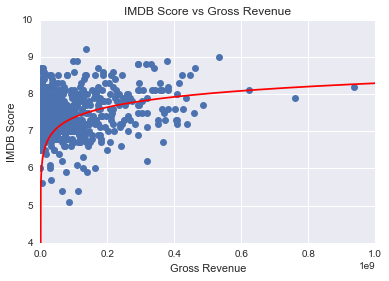
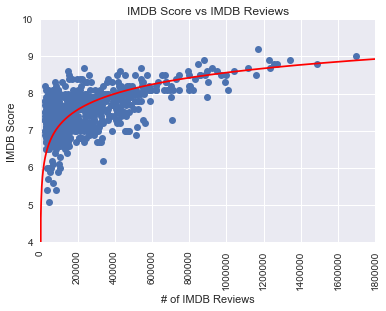
After incorporating these nonlinearities in the model, I ran some naive linear regressions to pick out which variables were significant predictors. As it turns out, all of my numerical feature variables (Metacritic score, runtime, log of number of reviews, log of domestic total gross revenue, Oscar wins, and budget) turned out to be statistically significant regressors at the 10% level of significance. I incorporated the categorical features as fixed effects by transforming them into a series of dummy variables, and whittled them down until all were significant at the 5% level of significance.
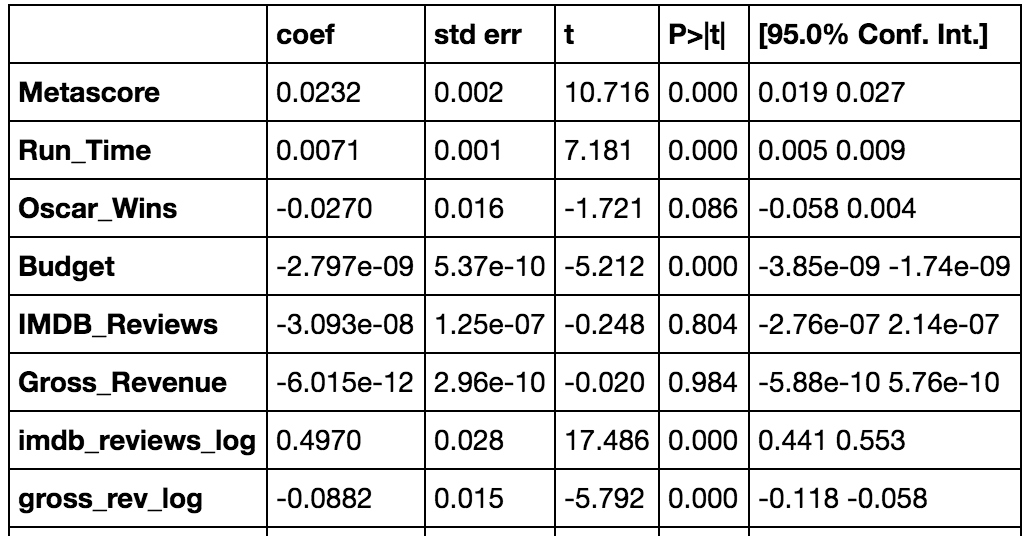
(Categorical dummy variables were left out of the above table display as they don’t aid in interpreting the numerical model coefficients, and are simply used to control for fixed effects)
One interesting finding is that Metacritic score and runtime both have positive and statistically significant effects on public review sentiment. I had a notion that ex ante, if a movie is received well by critics, it will upwardly bias a user’s review of the film. I was also curious if a longer runtime would have a positive or negative impact on review sentiment. One could argue that a longer runtime would mean a viewer is more likely to become bored of the film, but also allows the plot to develop more and garner viewer intrigue. We see that the latter effect wins out in the data, and that favorable critic reviews and longer runtime appear to positively influence the general public’s opinion of a movie. It’s also interesting to note that budget and number of Oscar wins negatively influence review sentiment. This could be for a number of reasons, but I would guess the most likely explanation is that action films and Hollywood blockbusters, which command high budgets and win awards for their visual effects, might not resonate as much with viewers than other genres. This is purely speculation, and would be interesting to look into further.
After completing the feature selection process, the next step was to run several different models and decide which one performed the best. I started by splitting the data into a 70% training set and 30% test set. I used the training set to fit the models I was running, and the test set to predict user scores from the test features and compare them to the actual test set target values. The models I chose to run were OLS, ridge, lasso and elastic net regressions, as well as random forest and gradient boosting models. After tuning the hyper parameters of the parametric regressions using a grid search cross validation, I tested their accuracies and found that ridge regression with a penalty coefficient of 1 performed the best. Specifically, it had a test set R-squared coefficient of 0.687, and thus explains a sizable majority of the variation in IMDB user score.
When taking a closer look at the performance of the ridge regression, it seems to perform fairly weel for movies that are rated highly, but performs less well for more poorly reviewed films. As we can see in the first plot below, the actual and predicted user scores hug the 45 degree line reasonably closely, but the predicted values are a bit inflated at lower scoring movies. This is apparent in the second plot below, which shows that the distribution of the residuals is slightly leftward skewed, implying some degree of upward inflation for the predicted scores.
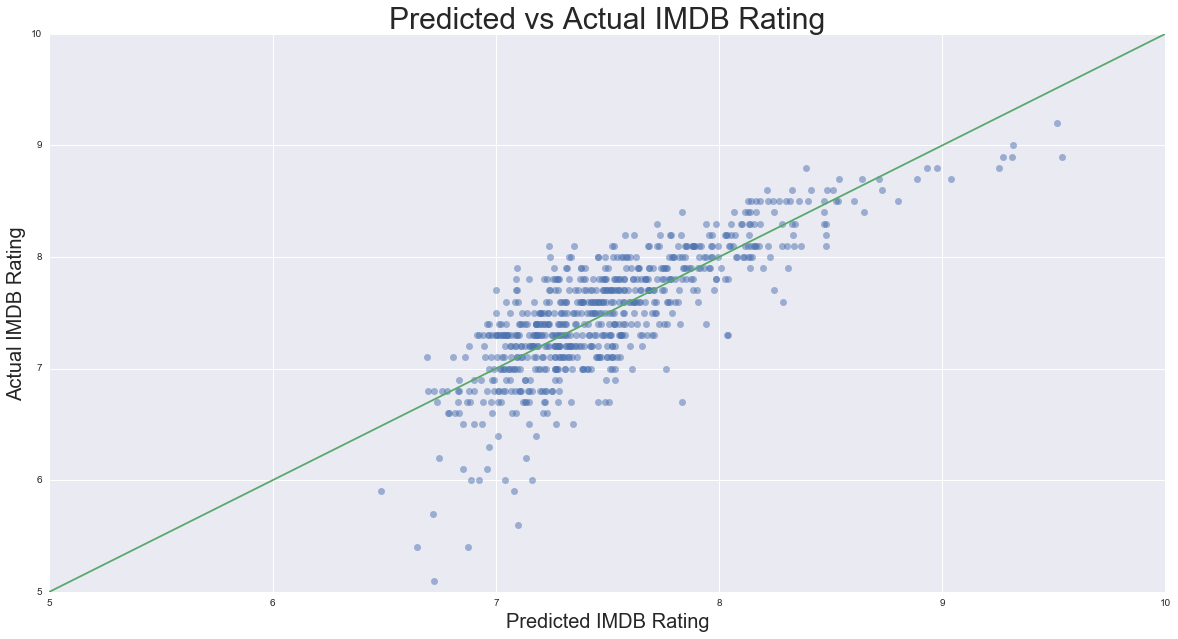
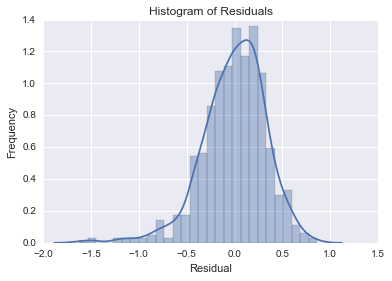
With that being said, there are some limitations to the predictive model specified. As I just mentioned, the model tends to over predict scores for poorer performing films. This could be a symptom of the fact that I scraped films by genre in descending order of score from the IMDB website. A remedy for this would be to scrape films with a wider range of user scores, and allow for a more robust training of the model. This would also increase sample size, which wasn’t small by any means, but could have been made larger to improve performance. Also, there may be a simultaneity issue since the number of IMDB use reviews and the user scores could very well be self reinforcing. Therefore, it is difficult to tease out the direction of causality between these two variables, and if the simultaneity does exist it could bias all of the coefficient values in the model. One remedy for this would be to use an instrumental variable on number of user reviews, and try to isolate the variation in this feature that influences user score. Either way, these are speculative considerations, and it remains to be seen if these potential improvements would increase the predictive capabilities of an already well performing model.
Some general thoughts on Project Luther and the bootcamp as a whole thus far:
- The first individual project was a bit of a reality check, but was a very rewarding experience.
- Presenting a project that is your own piece of work is fun and beneficial. The feedback you get on an individualized piece of work is very constructive, and should be welcomed at any point in time.
- The pace of the program is picking up and the amount of material we’ve already covered is piling up. Metis has really started to live up to its title of being a “bootcamp”.
- When working on a project with a lot of intermediate steps, it is helpful to assign yourself mini deadlines.
- Trying to get work done on weekends is tough. Finishing my work during the week has allowed me to explore San Francisco and really destress on Saturday and Sunday. This is a practice I hope to keep up, as the city has so much to offer and explore.
- The NBA season is right around the corner, so let the fanfare and friendly trash talk begin!